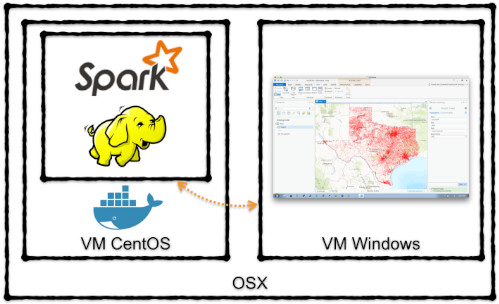
Been wanting to post on this subject for quite some time (actually over a year) as associating a world coordinate with the proper nearby linear feature provides tremendous insight based on the fusion of their attributes. Moreover, doing that on a massive scale and quickly is even more imperative in today's BigData world, thus the usage of Apache Spark. I’ve posted a standalone implementation that relies on well-documented simple math and published methodology to perform searches on massive datasets in batch mode. What is exciting to me in writing this post was the viewing of the snap results in ArcGIS Pro. My lack of knowledge in extending ArcGIS Pro with downloadable Python modules contributed to the delay (and slight case of procrastination :-). However, with the help of a colleague, I was able to pip install modules that can be imported by my custom ArcPy based toolboxes without any errors.
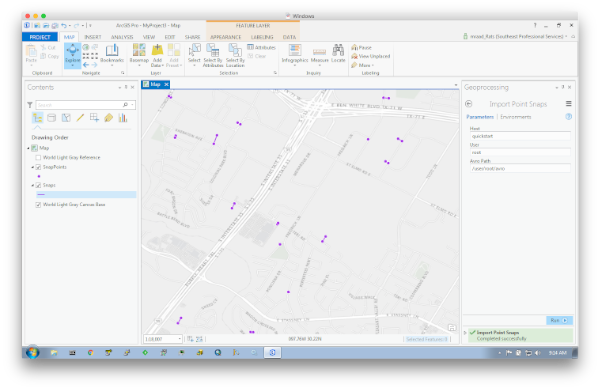
Also, since this is all based on BigData, well it has to be tested in a BigData environment. The post describes the usage of Docker and the Cloudera QuickStart container to check the snap and the visualization. The following illustrates my development environment.
Like usual, all the source code can be found here.
